.png)



In our last blogpost, we saw how external instruction sources referenced by skills manipulate the agent's actions with almost as much trust as the skill content itself. We also demonstrated how a once legit external documentation source can become malicious, given the dynamic nature of external sources and the current lack of vetting solutions for them.

Our experiment made the problem clear:
- Vetting a skill requires vetting its external resources, which is a blindspot of existing scanners
- Ensuring an external resource will never turn malicious is hard - very hard
As we demonstrated in the previous post, the skills and skills-marketplace landscape is a wild west of anonymous users uploading whatever they want. Anyone can upload a new skill referencing their made-up, never-heard-of web app or API documentation.
Yesterday (24.06.2026), following our latest research "The Story of Skills", OWASP recognized the risk of untrusted external instructions as on of the Agentic Skills Top 10 Risks list. This confirms what is now becoming clear - the risk external resources carry is deeply concerning, and reality moves faster than we realize.
All of this leaves us, defense practitioners, to dissect innocent community plugins from benign fronts ready to be maliciously rug-pulled.
The obvious question following our experiment: how widespread are such skills that reference untrusted external sources?
We decided to check.
The real-world brand-landingpage skills
Before starting our search, we had to nail down what we were actually hunting for.
We call an external resource untrusted if there’s no good reason for a third-party reviewer to trust it won’t turn malicious. In other words - a non-credible resource.
So if the core of the problem is vetting a link’s credibility, our research question sharpens: how widespread ARE those untrustworthy links?
We profiled how untrusted resources might be identified, then unleashed our scanners to find all skills that reference such untrusted resources. We ran them on the most popular skills on skills.sh and a wide corpus of GitHub skills, then waited patiently for them to come back. The results were not pretty.
Glancing Into The Wilderness
Before diving into the numbers, let’s get a taste of what kind of skills we are talking about.
Starting with a quick warmup, let’s take a look at ethskills. With >1600 agent installs, it claims to supply agents with knowledge on how to interact with the Ethereum crypto network. The skill starts by instructing the agent to fetch and follow ethskills.com/ship/SKILL.md. Just like that. External instructions at its finest.
It’s up to the author’s good will that those instructions stay benign. If one day he breaks bad, skill users will be infected without them knowing anything changed - as we demonstrated in our last blogpost.
%20(1).png)
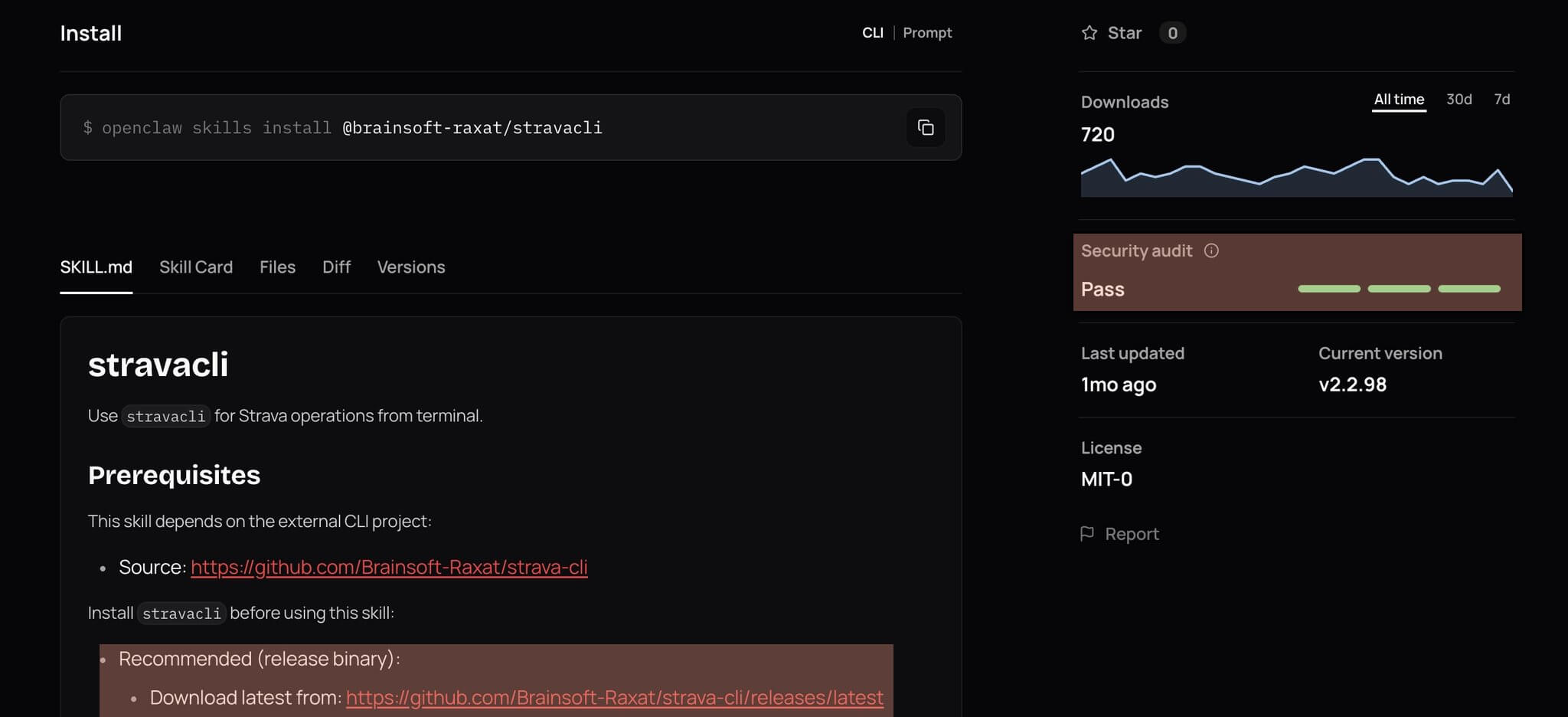
Another example is the Strava CLI Skill. With >700 downloads and an all-green PASS result from Nvidia’s security scanner on ClawHub, the skill claims to supply a cli tool to interact with your Strava account.
To install the CLI, it sends off the agent downloading a binary from github.com/Brainsoft-Raxat/strava-cli/releases/latest - a GitHub repository with no stars or forks, whose latest release could change at any time.
While not currently malware, can you trust the maintainer account Bransoft-Raxat, which has almost no recorded activity, followers or a real profile picture, to reliably maintain it? Can you trust him not to go rogue? Hard to tell.
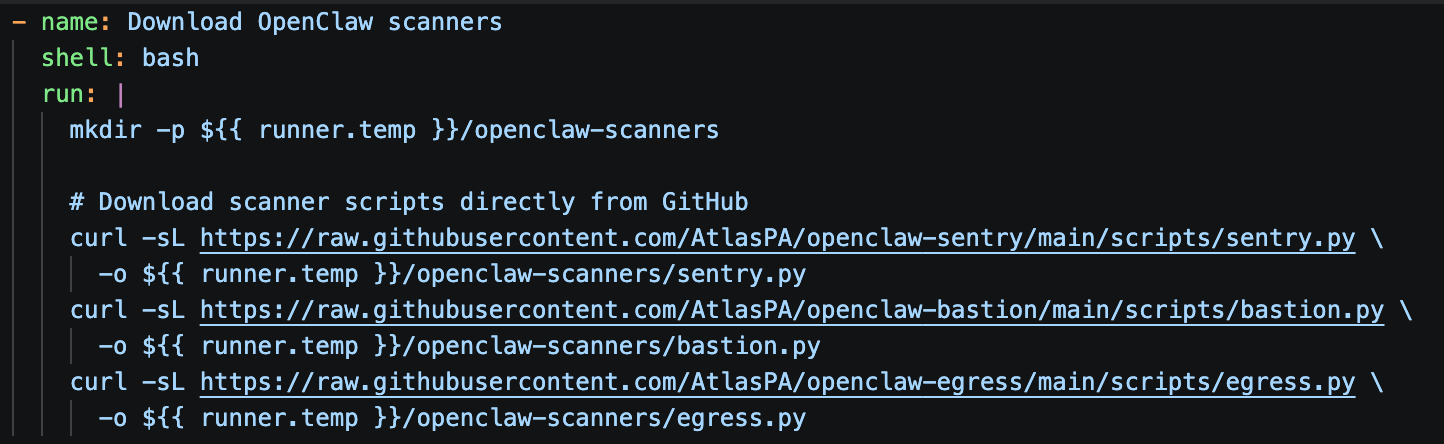
Lastly, a security tool called openclaw-action, with ~1.2K downloads on ClawHub. While the SKILL.md looks innocent - it even claims "no external dependencies" and "no network calls" - the skill ships an action.yml that defines a GitHub Action for the agent to embed in the users' repositories.
Each time the workflow defined in that injected GitHub Action is invoked - every PR, every push, or every week - the action fetches and executes three Python scripts, all under the full control of the skill author.
And this author you trust with your repos - you guessed it - is practically a ghost:

The day CreativeSteward decides to act, he has arbitrary Python RCE in every consumer's CI runner - with reach to the checked-out source, the GITHUB_TOKEN, and any workflow secrets.
This list could go on forever. Getting our hands dirty, an infinite stream of skills referencing made-up services on sketchy domains and zero credibility GitHub repos just kept pouring in. Really, it’s a mess out there. Let us show you just how much so.
It’s Not a Corner Case
We scanned 142,836 live skills - 9570 are the most popular skills on skills.sh, the other 133,266 pulled from the wider community on GitHub - and for each one extracted the external resources it hands the agent. Each external resource got assigned a trust score according to the number of signals it matched. One flag is just noise; a resource turns untrusted only when the signals add up. A skill inherits the score of its worst resource.
We expected the untrusted resources to be the exception. A weird corner of the ecosystem you’d have to go looking for.
Well, they weren’t.
17,822 skills - about 12.4% of everything we scanned - lean on at least one external resource we’d call untrusted. Every single one carries exactly the kind of link we abused in brand-landingpage: trusted by the agent, invisible to the scanner, and leaving the user with no way to judge whether it can be trusted.
Four Flavors of Fishy
We divided the extracted resources and trust signals into four families:
- Domains - the credibility of the web addresses themselves
- Github - the repos that host the skill, and repos referenced by it
- Code Packages - referenced registry packages. Those could be NPM, PyPI and so on.
- Hosts - the reliability and stability of the web app

Let’s take them one at a time, focusing on what each signal actually tells a reviewer. The skill and install counts behind every signal live in the Appendix at the end of the post.
Domains
Skills point the agent at web domains constantly - for docs, an API or a setup guide. And here’s the thing about domains: they are rented, not owned, and you cannot tell a rock-solid one from a throwaway burner just by reading the URL. Stability, ownership, who’s actually behind it - all invisible.
So we went looking for the domains a reviewer has no good reason to trust as stable - and no obvious reason to distrust, either. Sketchy, without a smoking gun. The signals we leaned on:
- Freshly registered - a domain registered less than a year ago, with no history to vouch for it.
- Cheap or free TLD - the
.xyz/.tk/.mlneighborhoods where bulk abuse clusters. - New and hidden - a brand-new domain that also tucks its registrant behind privacy protection.
- Brand look-alike - a single-keystroke look-alike of a brand you’d recognize on sight.
- Abuse-prone registrar - registered through a registrar overrepresented in public abuse reports, handling a disproportionate share of malicious domains.
And that’s not even the full signals list, as we’ll explore in future posts.
None of these is a smoking gun on its own. That’s the point - a person glancing at the link has nothing to go on, and yet 98 popular skills (~280K downloads) trip more than one of these signals, and across the full scan 3,409 skills rest on exactly that kind of “seems fine, can’t say why it isn’t” domain.
GitHub owners
This one isn’t about the content at all - it’s about who’s standing behind it. A link to a GitHub repo or gist is only as trustworthy as its contributors. An account that’s anonymous, brand-new, or barely used hasn’t done anything to earn that trust yet. In total, 782 popular skills (~5.3M downloads) are hosted on or reference an untrusted GitHub repo.
The signals we leaned on:
- Anonymous maintainer - most of the profile blank or actively configured as private. Not necessarily hiding anything - but nothing here tells a real person apart from a malicious front.
- Brand-new account - an account less than a year old.
- No track record - an account with almost no other public work to its name.
As with the domains, some of the signals will be explored in future posts.
Packages
This is the classic supply chain story. Unlike websites, a package is code the agent runs. Agents tend to trust “just pip install this” while treating a bare curl | bash with more suspicion - blind trust that an attacker will happily exploit. In total, 112 popular skills (~213K downloads) reference an untrusted external code package.
The signals we leaned on:
- Freshly published - a package first published less than three months ago, no track record at all.
- Typosquat - a package one keystroke off a popular one (
reqeustsforrequests, that whole genre). - Almost no downloads - a package with a very low download count. With so few users, a poisoned release would have almost no one watching to catch it.

Hosts
A domain is the address; the host is what actually answers when the agent knocks. And when a host misbehaves - refuses connections, 404s, serves a blank page - it’s a sign nobody’s tending this link anymore, and an unmaintained link is the dangerous kind: with no one guarding what it serves, nothing stops it from quietly turning into something else. Broken today - and no one’s making sure it doesn’t answer with something nasty tomorrow.
Free-tier hosting makes identity cheap and anonymous. When the host is a slot on a platform like Vercel, Netlify or Azure, there’s no ownership to inherit - a name like walmart.vercel.app goes to whoever signs up for it first. In total, 77 popular skills (~170K downloads) point at a resource on an untrusted host.
The signals we leaned on:
- Connection refused - a host that seems to be down and refusing to connect. This could be a temporary downtime, though more often a box that’s gone for good.
- 404 on the path - an app name that 404s on the referenced URI, a clear indicator for an abandoned app, with a high risk of an unwelcome replacement.
- Free-tier suffix - an app hosted on a free-tier suffix like
.vercel.appor.github.io: signaling a temporary prototype more than a production app, claimable by anyone the day that slot is freed.

The Bottom Line
Every untrusted skill is an untrusted link sitting inside someone’s agent, loaded with full trust, waiting. 6.7M installs ride on a skill with at least one untrusted external link.
That’s the number that should keep you up at night. Not because most skills are malicious - but because so many can’t be trusted to stay benign.
Takeaways for Organizations
Untrusted external instructions are a current gap in how we secure skills. Today’s scanners focus on the skill’s own content and miss the external resources it pulls in - and the very idea of vetting a skill once, at install time, breaks down when those resources can change underneath you at any moment. A skill that was clean when installed can quietly turn malicious without a single sentence or line of code changing.
Luckily, we can do better:
- Block skills with untrusted instruction sources. Vet every external resource a skill relies on based on the credibility of its source and the content of the domain it points to.
- Rescan external sources continuously. While auditing external resources is prone to time-of-check / time-of-use attacks, routinely rescanning your skills makes it harder for attackers to exploit the gap.
- Audit references transitively. When scanning, make sure you scan all the content fed to the agent by the skill - including the transitive external resources. Scans are a defense layer rather than a solution, but as such are still effective in making malicious actors' lives harder.
Appendix: The Numbers
For the figures, we focused on the 9,500 most popular skills on skills.sh, since those publish installation counts. Each entry below pairs a signal with the number of skills that matched it and their combined installs.
Domains
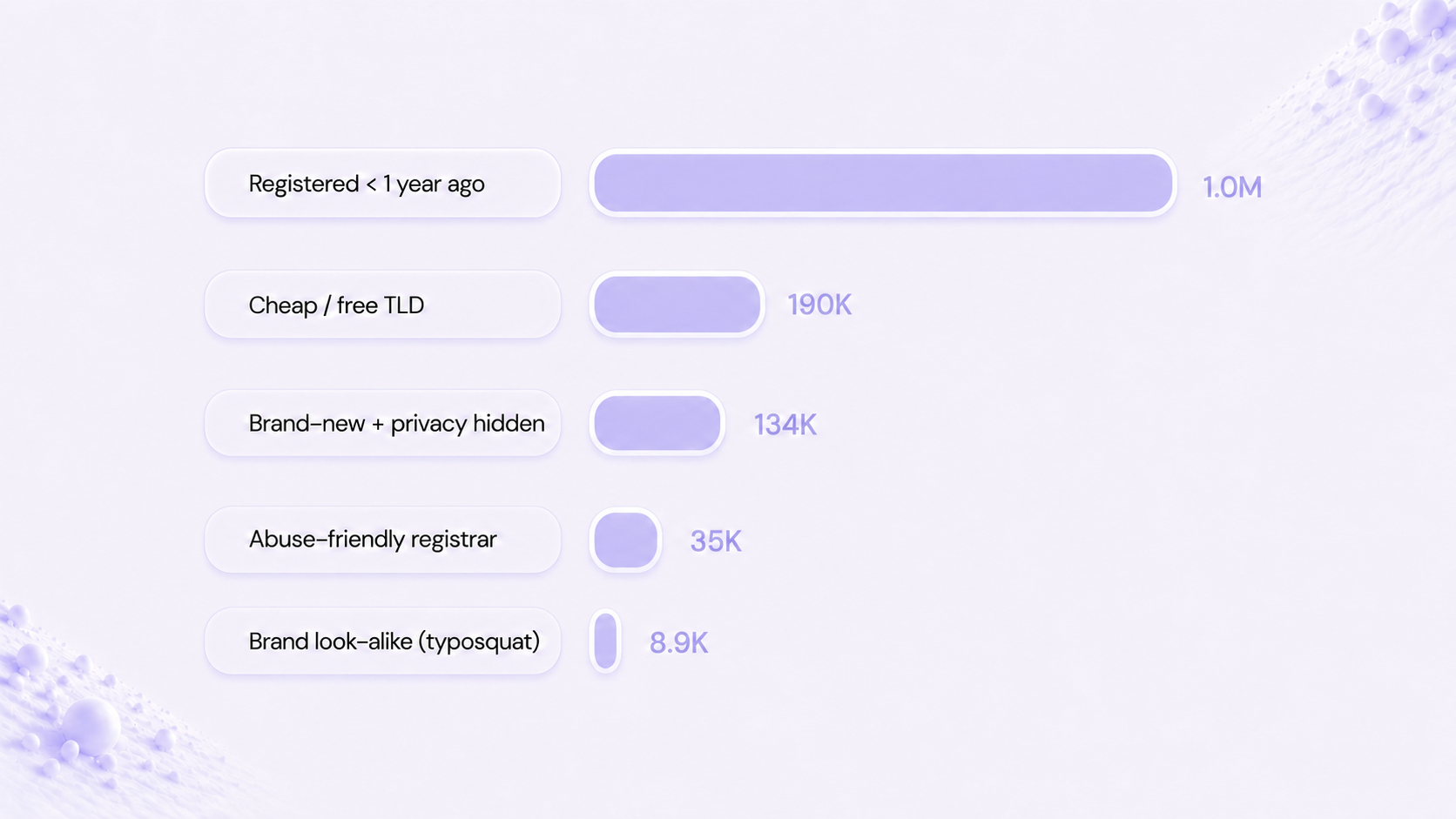
- Freshly registered (<1 year old) - 298 skills, ~1M installs.
- Cheap or free TLD (
.xyz/.tk/.ml) - 64 skills, ~190K installs. - New and privacy-protected - 39 skills, ~134K installs.
- Brand look-alike - 51 skills, ~9K installs.
- Abuse-prone registrar - 81 skills, ~35K installs.
GitHub Owners
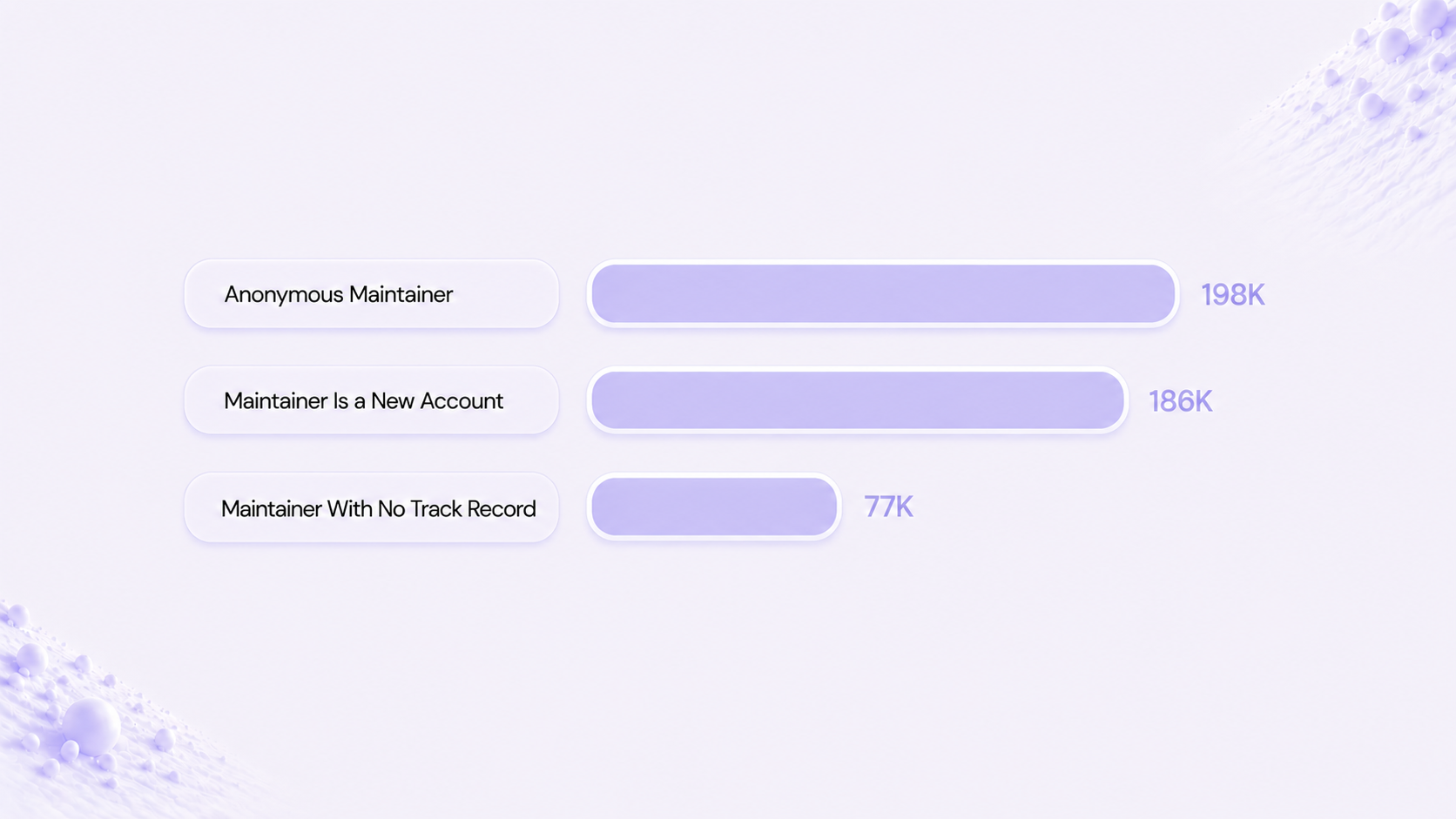
- Anonymous maintainer - 44 skills, ~198K installs.
- Account <1 year old - 20 skills, ~186K installs.
- No track record - 38 skills, ~77K installs.
Packages
- Published <3 months ago - 195 skills, ~1.07M installs.
- Typosquat - 37 skills, ~66K installs.
- Very low download count - 6 skills, ~60K installs.
Hosts
- Connection refused - 821 skills, ~10.5M installs.
- 404 on the path - 454 skills, ~3.5M installs.
- Free-tier suffix - 98 skills, ~1.6M installs.
.png)

.webp)